
پیشبینی زمان تحویل کالا : مقایسه روشهای آماری پیشبینی با شبکههای عصبی در دنیای واقعی
پیشبینی زمان تحویل کالا در دنیای مدیریت پروژه، بسیار حیاتی است؛ چراکه هیچ چیز به اندازهی «دیر رسیدن یک کالا» نمیتواند زنجیره تصمیمگیری را بههم بریزد. اگر در تأمین بهموقع یک قطعه حیاتی تأخیر بیفتد، کل برنامهی تولید یا اجرای پروژه میتواند دچار توقف شود. یک اشتباه در برآورد زمان تحویل، یعنی هزینهی خواب سرمایه، توقف کارگاه، یا حتی از دست رفتن قرارداد. مدیران لجستیک و پروژه هر روز با همین بازی زمان سروکار دارند :
- تأمینکننده قول ۵ روز داده، اما آیا واقعاً ۵ روزه میرسد؟
- در شرایط فعلی حملونقل و تحریمها، چقدر احتمال تأخیر داریم؟
- آیا باید برای اطمینان، سفارش دوم بدهیم یا هزینهی انبار را بپذیریم؟
پاسخ به این پرسشها، تنها با تجربه یا حدس زدن ممکن نیست. به همین دلیل سازمانها از دههها قبل بهدنبال روشهای تحلیلی برای پیشبینی زمان دریافت کالا رفتهاند؛ از محاسبات سادهی میانگین و قوانین شرطی گرفته تا مدلهای آماری و یادگیری ماشینی. اما واقعیت این است که بسیاری از سازمانها هنوز در مرحلهی منطق If–Then–Else گیر کردهاند. یعنی همان جایی که پیشبینی زمان تحویل، نه بر اساس یادگیری از دادههای واقعی، بلکه بر پایهی مجموعهای از قواعد دستی و تجربهمحور انجام میشود. قواعدی که در ظاهر دقیقاند، اما در عمل با هر تغییر کوچک در زنجیرهی تأمین از کار میافتند. و درست از همین نقطه است که هوش مصنوعی و شبکههای عصبی وارد میدان میشوند تا با تکیه بر دادههای تاریخی، الگوهای پنهان، و روابط غیرخطی، پیشبینی دقیقتر و هوشمندانهتری از زمان دریافت کالا ارائه دهند.
روشهای سنتی پیشبینی: میانگینگیری و منطق If–Then–Else
اولین تلاش سازمانها برای پیشبینی زمان تحویل، معمولاً از سادهترین نقطه شروع میشود: میانگینگیری. مثلاً اگر پنج محموله گذشته از یک تأمینکننده، به ترتیب در ۳، ۵، ۴، ۶ و ۵ روز رسیده باشند، میانگین آنها یعنی ۴.۶ روز، میشود پیشبینی تحویل بعدی. در نگاه اول این روش بد نیست؛ سریع است، قابلفهم است، و بدون نیاز به ابزار پیچیده کار میکند. اما بهمحض تغییر کوچک در شرایط مثلاً ترافیک بندر، نوسان ارزی یا خرابی کامیون کل محاسبه بیارزش میشود. چرا؟ چون میانگین، رفتار واقعی سیستم را نمیفهمد، فقط عددها را صاف میکند. به مرور، برای دقیقتر شدن، روشها پیچیدهتر میشوند: میانگین متحرک، وزندار، یا حتی مدلهای رگرسیون خطی وارد صحنه میشوند تا وابستگی زمان تحویل به عواملی مثل فاصله، نوع حمل یا حجم سفارش را پیدا کنند. اما در عمل، بسیاری از سازمانها هنوز هم به یک ابزار سنتیتر تکیه میکنند: منطق If–Then–Else
منطق If–Then–Else؛ ساده، قابلدرک، اما شکننده
منطق If–Then–Else اساساً یعنی “اگر این اتفاق افتاد، آن کار را انجام بده.” در محیطهای لجستیکی، این منطق در قالب دهها یا صدها قاعده شرطی پیادهسازی میشود. مثلاً در اکسل، ERP یا حتی نرمافزارهای داخلی چنین قواعدی رایجاند:
اگر نوع حمل = هوایی و کشور مبدأ = ترکیه، آنگاه زمان تحویل = ۳ روز
اگر نوع حمل = دریایی و کشور مبدأ = چین، آنگاه زمان تحویل = ۲۵ روز
اگر مسیر = زمینی و حجم سفارش > ۵ تن، آنگاه زمان تحویل = ۷ روز
در ظاهر، این ساختار ساده و شفاف است. مدیر پروژه میداند منطق تصمیم چیست، برنامهنویس میتواند آن را در سیستم بنویسد، و تحلیلگر هم میتواند در اکسل تستش کند. اما در عمل، این روش مثل خانهای است که با آجرهای زیاد ساخته میشود، بدون اینکه اسکلت داشته باشد. هر چه متغیرهای جدیدی وارد شوند مثل فصل سال، تأخیر گمرک، وضعیت ارزی، یا حتی رفتار تأمینکننده باید شرطهای بیشتری اضافه شود. نتیجه؟ یک جنگل از قواعد تو در تو، که کوچکترین تغییر در یکی از آنها میتواند پیشبینی کل سیستم را خراب کند. بهمرور، سازمان وارد چرخهای فرسایشی میشود:
- هر بار تأخیری پیشبینی نشده رخ میدهد، یک شرط جدید اضافه میشود.
- هر بار شرط جدیدی جواب نمیدهد، شرط بعدی مینویسند.
- این داستان ادامه دارد، تا جایی که دیگر هیچکس نمیداند کدام قانون واقعاً درست کار میکند.
- مثل یک برنامه بزرگ پر از وصله و پینه!
محدودیتهای رویکرد آماری و شرطی
مشکل اصلی این روشها در ۳ چیز خلاصه میشود:
- وابستگی شدید به تجربه انسانی: اگر کارشناس باتجربه برود، دانش سیستم هم از بین میرود.
- ناتوانی در یادگیری: این مدلها از دادههای گذشته یاد نمیگیرند. فقط تکرار میکنند.
- پیچیدگی پیادهسازی!
به همین دلیل است که سازمانها در عصر داده محور، بهدنبال رویکرد داده کاوی هستند که بتواند:
- الگوهای پنهان در دادهها را کشف کند
- شرایط پویا را درک کند
- و خودش را با رفتار واقعی تأمینکنندگان تطبیق دهد.
و این همان نقطهای است که شبکههای عصبی وارد میشوند.
شبکههای عصبی مصنوعی چیستند و چرا متفاوت فکر میکنند؟
برای درک تفاوت بین روشهای آماری و شبکههای عصبی، کافی است تصور کنیم در مغز انسان چه اتفاقی میافتد وقتی میخواهد چیزی را پیشبینی کند. مغز ما از میلیاردها سلول عصبی (نورون) ساخته شده که هر کدام سیگنالهایی را از سایر سلولها دریافت میکنند، آنها را پردازش میکنند و نتیجه را به سلولهای بعدی میفرستند. این فرآیند بسیار سریع، پویا و تطبیقپذیر است، یعنی مغز میتواند از تجربههای گذشته یاد بگیرد و در شرایط جدید تصمیمهای متفاوت بگیرد. شبکههای عصبی مصنوعی (Artificial Neural Networks) دقیقاً از همین ایده الهام گرفتهاند.
در سادهترین شکل، آنها مجموعهای از گرهها (نودها) هستند که در لایههایی به هم وصل شدهاند:
- لایه ورودی: دادهها وارد میشوند (مثلاً فاصله، نوع حمل، تأمینکننده، فصل، وزن کالا و غیره)
- لایههای میانی (پنهان): دادهها ترکیب و پردازش میشوند؛ اینجا همانجایی است که مدل روابط پیچیده بین متغیرها را یاد میگیرد.
- لایه خروجی: نتیجه پیشبینی میشود (مثلاً “احتمال تأخیر” یا “زمان تحویل مورد انتظار”).
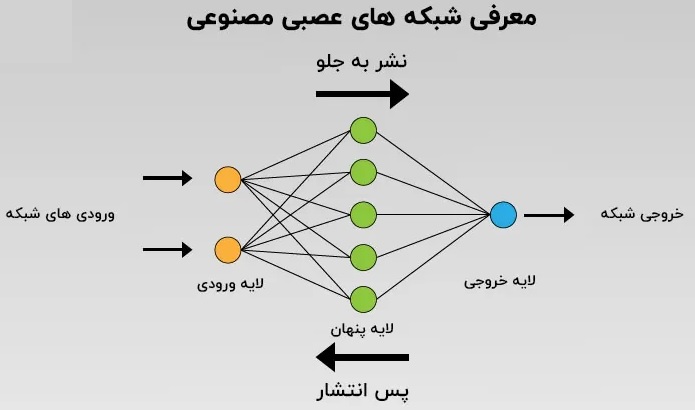
برخلاف روشهای آماری که فرض میکنند رابطه بین متغیرها خطی است (یعنی اگر فاصله دو برابر شود، زمان تحویل هم دو برابر میشود)، شبکههای عصبی هیچ فرضی از پیش ندارند. آنها بهجای تعریف رابطه، رابطه را یاد میگیرند.
به زبان سادهتر:
- در روش آماری، ما به مدل میگوییم رابطه چیه.
- در شبکه عصبی، دادهها به مدل میگویند رابطه چیه.
برای مثال، اگر در دادههای تاریخی دیده شود که تأخیر در زمستان برای مسیر بندرعباس همیشه ۲۰٪ بیشتر است، شبکه عصبی خودش این الگو را کشف میکند بدون اینکه کسی شرطی بنویسد یا میانگینی محاسبه کند. هرچه دادهها بیشتر و متنوعتر باشند، شبکه دقیقتر یاد میگیرد. به همین دلیل است که امروزه از شبکههای عصبی برای پیشبینیهای بسیار پیچیده استفاده میشود: از پیشبینی ترافیک جادهها و نوسان قیمت سوخت گرفته تا زمان واقعی تحویل کالا در زنجیرههای جهانی تأمین.
شبکه عصبی، آشپزی خلاق و یادگیرنده
در مقابل، شبکههای عصبی شبیه آشپزی هستند که تجربه دارد و خودش تصمیم میگیرد: او میتواند رابطه پیچیده بین چندین عامل را درک کند (مثلاً حجم سفارش + مسیر + تأمینکننده + فصل + شرایط حمل).
که با دیدن دادههای جدید، خود را تطبیق میدهد و پیشبینی بهتری ارائه میکند. هیچ کسی نیازی ندارد هر شرط را دستی تعریف کند؛ شبکه خودش الگوها را کشف میکند.
مثلاً در پیشبینی زمان تحویل:
- مدل If–Then–Else فقط میتواند بگوید «اگر مسیر بندری است، ۲۰ روز».
- شبکه عصبی میتواند بگوید «با توجه به تاریخهای گذشته، حجم سفارش، وضعیت گمرک، و شرایط فصل، احتمالاً تحویل در ۱۸ تا ۲۲ روز رخ میدهد و حتی احتمال تأخیر ۲۵٪ است»
مزیت عملی شبکه عصبی در سازمان
- انعطافپذیری بالا: با تغییر دادهها، مدل خود را بهروز میکند.
- پیشبینی دقیقتر: روابط غیرخطی و پنهان بین متغیرها را کشف میکند.
- صرفهجویی در زمان و منابع: دیگر نیازی نیست صدها قانون If–Then–Else نوشته و نگهداری شود.
- تصمیمگیری هوشمند: مدیران میتوانند بر اساس پیشبینی واقعی و نه حدس، موجودی و برنامهی لجستیک را تنظیم کنند.
در واقع، تفاوت فلسفی این است:
- If–Then–Else میگوید: «دستور بده و اجرا کن».
- شبکه عصبی میگوید: «یاد بگیر، پیشبینی کن و خودت تصمیم بگیر».
و همین، پل بین روشهای سنتی و عصر هوش مصنوعی در زنجیره تأمین است.
طراحی داشبورد پیشبینی زمان تحویل کالا با شبکه عصبی
یک داشبورد پیشبینی خوب ترکیبی است از تحلیل تاریخی، پیشبینی هوشمند و نمایش بصری ساده. هدف این است که مدیر بتواند در یک نگاه:
- وضعیت تحویل همه کالاها را ببیند،
- تأخیرها و ریسکها را تشخیص دهد،
- و سریع تصمیم بگیرد که آیا اقدام پیشگیرانه نیاز است یا نه.
۱. ورودیهای دادهای و اهمیت حجم داده : برای پیشبینی دقیق، داشبورد باید دادههای متنوع زیر را دریافت کند:
| نوع داده | مثال |
|---|---|
| مشخصات سفارش | حجم، وزن، نوع کالا |
| اطلاعات تأمینکننده | کشور، سوابق تحویل، قابلیت اعتماد |
| مسیر حمل | زمینی، دریایی، هوایی |
| شرایط زمانی | فصل، تعطیلات، وضعیت آب و هوا |
| دادههای تاریخی | تأخیرهای گذشته، میانگین زمان تحویل |
| وضعیت تحریم | در مسیر تحریم است |
جدول ساختار دادههای قابل انتقال به شبکه عصبی جهت یادگیری
نکته کلیدی: هرچه حجم و تنوع دادهها بیشتر باشد، شبکه عصبی دقیقتر و هوشمندتر پیشبینی میکند. این یعنی شبکه میتواند الگوهای پیچیده و غیرخطی پنهان را کشف کند که با روشهای سنتی یا قواعد شرطی قابل شناسایی نیستند.
۲. پردازش و پیشبینی:
لایه ورودی: دادههای خام وارد میشوند.
- لایههای پنهان: شبکه عصبی روابط پیچیده بین متغیرها را یاد میگیرد. هر داده جدید، مدل را بهتر میکند.
- لایه خروجی: زمان پیشبینیشده تحویل و احتمال تأخیر ارائه میشود.
این پیشبینی میتواند به دو شکل نمایش داده شود:
- مقدار دقیق زمان تحویل (مثلاً ۵/۲ روز)
- محدوده احتمالی و ریسک تأخیر (مثلاً احتمال ۲۰٪ تأخیر بیشتر از ۷ روز)
۳. نمایش بصری (Visualization)
داشبورد باید برای مدیران ساده و قابل فهم باشد، مثل:
- نوار زمان (Timeline): وضعیت هر محموله، تاریخ تحویل پیشبینیشده و میزان ریسک
- نقشه مسیر: نمایش جغرافیایی تأمینکننده و مسیر حمل
- نمودار ریسک: احتمال تأخیر بر اساس تأمینکننده، مسیر و نوع کالا
- هشدارهای هوشمند: سیستم به صورت خودکار به مدیر اعلام میکند که محمولهای با ریسک بالا نیاز به بررسی دارد
مهم: با هر داده جدیدی که وارد سیستم میشود، شبکه عصبی یاد میگیرد و پیشبینیها دقیقتر و قابل اعتمادتر میشوند. این همان ویژگی «هوش واقعی» است که روش سنتی ندارد.
۴. مزیت عملی
با این داشبورد، مدیر دیگر به حدس و تجربه متکی نیست، بلکه با اطمینان دادهمحور تصمیم میگیرد:
- آیا باید سفارش جایگزین بدهد؟
- موجودی انبار چقدر باید باشد؟
- منابع لجستیک را چگونه تخصیص دهد؟
در واقع، این داشبورد همان پلی است که روش سنتی و شبکه عصبی را به یک ابزار عملی و کاربردی برای تصمیمگیری واقعی تبدیل میکند.
یادگیری مستمر شبکه عصبی و ارتباط با دادههای نرم افزار BPMS
یکی از کلیدیترین ویژگیهای شبکه عصبی در پیشبینی زمان تحویل کالا ،توانایی یادگیری مستمر از دادههای واقعی سازمان است. این داده از سورس مختلف قابل انتقال است. یکی از سورس میتواند یک نرم افزار BPMS باشد . هر بار که فرایندهای مرتبط با تحویل کالا در BPMS رصد میشوند — مانند وضعیت سفارش، مسیر حمل، عملکرد تأمینکننده، حجم و نوع کالا، شرایط زمانی و حتی تغییرات ناگهانی — این دادهها میتوانند به شبکه عصبی داده شوند تا مدل بهصورت پویا خود را بهروزرسانی کند.
نتیجه این است که:
- مدل با هر بار ورود داده، دقیقتر میشود.
- پیشبینیهای آینده نه تنها بر اساس دادههای تاریخی، بلکه بر اساس وضعیت جاری و واقعی فرآیندهای تعریف شده در نرم افزار BPMS انجام میشود.
- سازمان میتواند تصمیمات سریع و دادهمحور بگیرد و ریسک تأخیر را کاهش دهد.
به عبارت ساده: نرم افزار BPMS دادههای فرآیندهای تحویل کالا را فراهم میکند، شبکه عصبی این دادهها را تحلیل و یاد میگیرد، و هر بار که داده جدیدی وارد میشود، پیشبینیها دقیقتر و قابل اعتمادتر میشوند. این همان نقطهای است که سیستم سنتی If–Then–Else هرگز نمیتواند به آن برسد. روش سنتی فقط تکرار میکند، اما شبکه عصبی با هر رصد دیتا، هوشمندتر میشود.
امکان پیادهسازی شبکه عصبی
اگر فکر میکنید شبکه عصبی چیز پیچیدهای است که فقط دانشمندان داده میتوانند بسازند، باید بگویم که امروزه با کتابخانههای آماده و ابزارهای متنباز، پیادهسازی شبکه عصبی بسیار ساده شده است.
- زبانهای برنامهنویسی مانند Python با کتابخانههای معروفی مثل TensorFlow، Keras و PyTorch، به شما امکان میدهند شبکههای عصبی را در چند خط کد بسازید، آموزش دهید و پیشبینی کنید.
- دادههای واقعی استخراجشده از BPMS میتوانند مستقیماً به این مدلها داده شوند و شبکه، پیشبینی زمان تحویل کالا را به صورت پویا و دقیق انجام دهد.
- با این روش، سازمانها میتوانند نسخه اولیه شبکه عصبی را سریعاً اجرا کرده و پس از جمعآوری دادههای بیشتر، دقت آن را بهبود دهند.
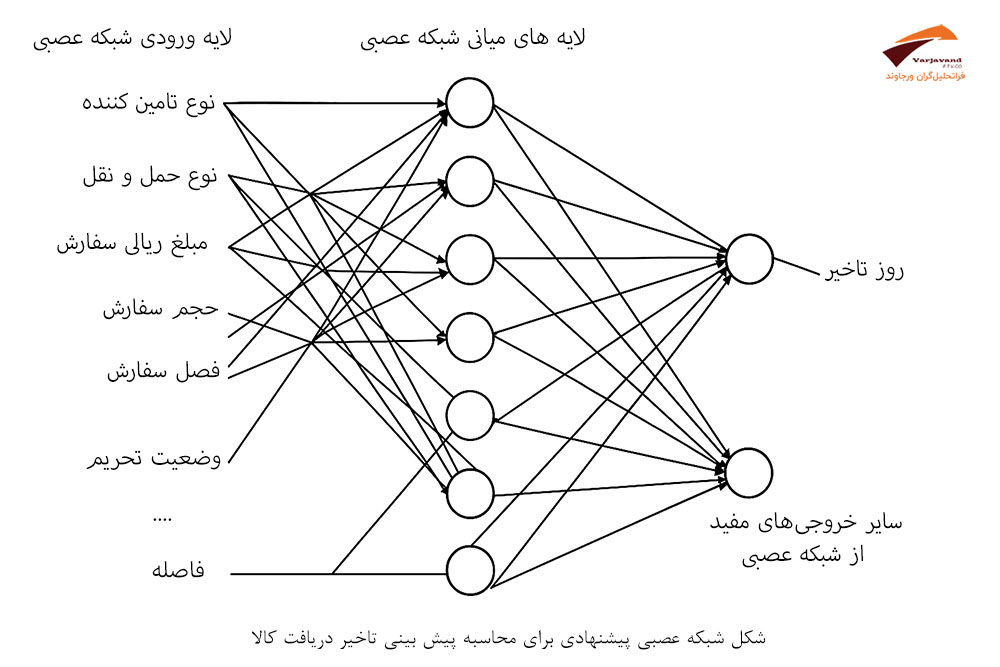
تصویر شبکه عصبی که ارائه شده، نشان میدهد چگونه دادهها از لایه ورودی عبور کرده، پردازش میشوند و در لایه خروجی پیشبینی نهایی تولید میشود. این تصویر میتواند درک بصری خواننده را از فرآیند یادگیری شبکه عصبی به شدت افزایش دهد.
| نوع تامین کننده | نوع حمل | مبلغ (ارزش مالی) | حجم (تعداد واحد یا تن) | فصل | تحریم پذیر | فاصله | تاخیر |
|---|---|---|---|---|---|---|---|
| داخلی | زمینی | ۵۰ | ۱۰۰۰ | بهار | خیر | ۲۰۰ | ۳ |
| خارجی | دریایی | ۲۰۰ | ۱۵۰۰۰ | تابستان | بله | ۱۵۰۰ | ۱۸ |
| داخلی | هوایی | ۳۰ | ۸۰۰ | پاییز | خیر | ۵۰۰ | ۲ |
| خارجی | زمینی | ۱۰۰ | ۷۰۰۰ | زمستان | خیر | ۱۲۰۰ | ۱۰ |
| داخلی | دریایی | ۱۵۰ | ۱۲۰۰۰ | بهار | خیر | ۸۰۰ | ۱۲ |
| خارجی | هوایی | ۷۰ | ۵۰۰۰ | تابستان | بله | ۲۰۰۰ | ۵ |
| داخلی | زمینی | ۴۰ | ۹۰۰ | پاییز | خیر | ۱۰۰ | ۲ |
| خارجی | دریایی | ۲۵۰ | ۲۰۰۰۰ | زمستان | بله | ۱۸۰۰ | ۲۰ |
| داخلی | هوایی | ۲۰ | ۶۰۰ | بهار | خیر | ۳۰۰ | ۱ |
| خارجی | زمینی | ۱۸۰ | ۱۴۰۰۰ | تابستان | خیر | ۱۳۰۰ | ۱۵ |
جدول نمونه دیتا ورودی جهت آموزش شبکه عصبی
نتیجهگیری
پیشبینی زمان تحویل کالا یکی از چالشهای اصلی سازمانها در مدیریت لجستیک و پروژه است. روشهای سنتی مانند میانگینگیری یا قواعد شرطی If–Then–Else ساده و قابل فهم هستند، اما محدودیتهای جدی دارند: وابستگی به تجربه انسانی، ناتوانی در یادگیری از دادههای جدید و شکنندگی در برابر تغییر شرایط. شبکههای عصبی مصنوعی، در مقابل، با الهام از مغز انسان، قادرند الگوهای پیچیده و غیرخطی بین متغیرها را کشف کنند و بر اساس دادههای واقعی پیشبینی کنند. هنگامی که این مدلها با BPMS ترکیب شوند، مزایای زیر حاصل میشود:
- دادههای واقعی فرآیندها: شبکه عصبی میتواند اطلاعات لحظهای و تاریخی از BPMS دریافت کند، مانند وضعیت سفارشها، مسیر حمل، عملکرد تأمینکننده و شرایط زمانی.
- یادگیری مستمر: هر بار که داده جدید وارد سیستم میشود، پیشبینیها دقیقتر و هوشمندتر میشوند و مدل بهصورت پویا خود را بهبود میبخشد.
- تصمیمگیری دادهمحور: مدیران میتوانند با اطمینان بر اساس پیشبینیهای واقعی تصمیم بگیرند، منابع را بهینه تخصیص دهند و ریسک تأخیر را کاهش دهند.
- بهبود مستمر فرآیندها: ترکیب BPMS و شبکه عصبی یک چرخهی یادگیری دائمی ایجاد میکند، که هر بار داده جدید، پیشبینیها و عملکرد سازمان را تقویت میکند.
در نهایت، سازمانهایی که از این رویکرد استفاده میکنند، از حدس و تجربه گذشته فراتر رفته و به تصمیمگیری سریع، دقیق و هوشمند دست پیدا میکنند. این همان جهشی است که روش سنتی هرگز نمیتواند ارائه دهد و نشان میدهد که آینده پیشبینی زمان تحویل کالا ، در ترکیب دادههای واقعی BPMS و هوش مصنوعی است. پیشبینی زمان تحویل کالا یکی از چالشهای اصلی سازمانها در مدیریت لجستیک و پروژه است. روشهای سنتی مانند میانگینگیری یا قواعد شرطی If–Then–Else ساده و قابل فهم هستند، اما محدودیتهای جدی دارند: وابستگی به تجربه انسانی، ناتوانی در یادگیری از دادههای جدید و شکنندگی در برابر تغییر شرایط. شبکههای عصبی مصنوعی، در مقابل، با الهام از مغز انسان، قادرند الگوهای پیچیده و غیرخطی بین متغیرها را کشف کنند و بر اساس دادههای واقعی پیشبینی کنند. هنگامی که این مدلها با BPMS ترکیب شوند، مزایای زیر حاصل میشود:
- دادههای واقعی فرآیندها: شبکه عصبی میتواند اطلاعات لحظهای و تاریخی از BPMS دریافت کند، مانند وضعیت سفارشها، مسیر حمل، عملکرد تأمینکننده و شرایط زمانی.
- یادگیری مستمر: هر بار که داده جدید وارد سیستم میشود، پیشبینیها دقیقتر و هوشمندتر میشوند و مدل بهصورت پویا خود را بهبود میبخشد.
- تصمیمگیری دادهمحور: مدیران میتوانند با اطمینان بر اساس پیشبینیهای واقعی تصمیم بگیرند، منابع را بهینه تخصیص دهند و ریسک تأخیر را کاهش دهند.
- بهبود مستمر فرآیندها: ترکیب BPMS و شبکه عصبی یک چرخهی یادگیری دائمی ایجاد میکند، که هر بار داده جدید، پیشبینیها و عملکرد سازمان را تقویت میکند.
در نهایت، سازمانهایی که از این رویکرد استفاده میکنند، از حدس و تجربه گذشته فراتر رفته و به تصمیمگیری سریع، دقیق و هوشمند دست پیدا میکنند. این همان جهشی است که روش سنتی هرگز نمیتواند ارائه دهد و نشان میدهد که آینده پیشبینی زمان تحویل، در ترکیب دادههای واقعی BPMS و هوش مصنوعی است.





